[DL] GAN 논문 리뷰
기존의 컴퓨터 비전 분야의 딥러닝 연구는 주로 이미지의 분류(Classification), 탐지(Detection), 분할(Segmentation)에 집중하여 이뤄졌습니다. 하지만 현재는 위의 세 분야와 더불어 이미지 생성(Generation) 에 대한 연구가 활발히 진행되고 있습니다. 이전에도 이미지 생성에 대한 연구가 진행되었지만 GAN 등장 이후로 이미지 생성에 대한 관심이 폭발적으로 증가하였습니다. GAN은 모델이 학습이 아닌 경쟁을 통해 이미지를 만들어내는 개념을 통해 이전의 방식보다 좋은 성능을 보여주고 있습니다. 저도 GAN에 대해 기본적인 부분에 대해서는 알고 있었지만(경찰과 위조 화폐범의 예시 정도;) 보다 심도 있는 작동 원리를 파악하고자 GAN 논문인 Generative Adversarial Nets에 대해 살펴보았습니다.

직관적으로 알고 가야할 점
- GAN 모델은 가상의 이미지를 생성하는 생성자(Generator) 모델과 가상의 이미지와 실제 이미지의 진위 여부를 판단하는 판별자(Discriminator) 모델로 구성되어 있습니다. 생성자 모델은 판별자 모델을 속일 수 있는 실제와 비슷한 이미지를 생성하도록 학습하고 판별자 모델은 실제 이미지와 생성자 모델이 생성한 가상의 이미지를 구별할 수 있도록 학습합니다. 이와 같이 두 모델은 서로 적대적으로 경쟁하며 성능을 발전시킵니다. 이에 대한 예로 화폐 위조범과 경찰의 예를 들 수 있습니다. (저는 GAN에 대한 설명을 쉽게 하기 위해 블로그에서 추가한 예시라 생각했는데 실제 논문에 예시가 기재되어 있어 놀랐습니다.)
The generative model can be thought of as analogous to a team of counterfeiters,trying to produce fake currency and use it without detection, while the discriminative model is analogous to the police, trying to detect the counterfeit currency. Competition in this game drives both teams to improve their methods until the counterfeits are indistiguishable from the genuine articles.
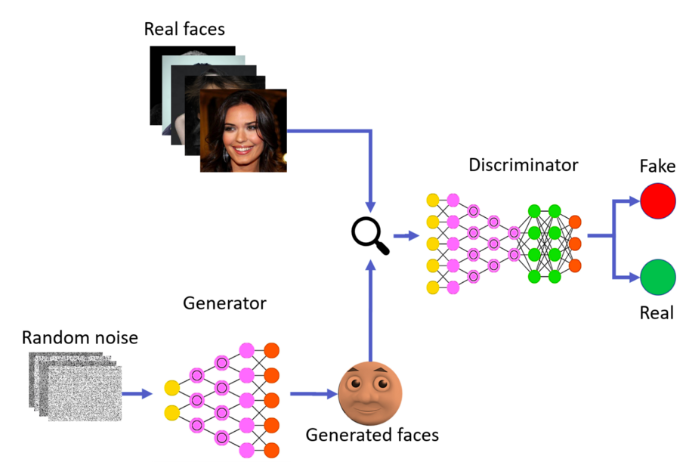
- 생성자 모델이 학습하는 것은 실제 이미지의 데이터 분포(data distribution)입니다. 만약 데이터의 분포에 근사한다면 실제 이미지와 비슷한 이미지를 생성해낸다고 할 수 있습니다. 생성자 모델은 가우시안 분포의 random noise를 입력받아 가상의 이미지를 출력하고, 판별자 모델은 가상의 이미지와 실제 이미지, 그리고 label을 입력 받아 이미지의 진위 여부(실제 이미지일 경우 1, 가상의 이미지일 경우 0)를 출력합니다.
GAN 알고리즘

위의 그림은 논문에 수록된 GAN의 학습과정 그래프입니다.
- 여기서 z는 random noise로부터 추출한 데이터이고, x는 실제 데이터입니다. z에서 x로의 화살표는 생성자 모델이 실제 데이터로 mapping하는 것을 의미합니다.
- 녹색선은 생성자 모델이 생성한 데이터의 분포, 검은 점선은 실제 데이터의 분포, 파란점선은 판별자의 분포를 나타냅니다.
- (a)에서 (d)로 나가가면서 생성자의 분포가 실제 데이터의 분포와 닮아가는 것을 확인할 수 있습니다. 이와 동시에 판별자의 분포는 일직선을 이루게 되는데 이는 판별자가 실제 데이터와 가상의 데이터를 판별하는 확률이 1/2, 즉 가상과 실제를 구분할 수 없음을 의미합니다(그 정도로 가상의 데이터가 잘 만들어진 것입니다!).

GAN은 먼저 (다음 과정을 k번 반복합니다)
- noise data를 m개만큼 추출하고, 실제 데이터로부터 m개의 sample을 추출합니다.
- 1번에서 추출한 데이터를 활용하여 판별자 모델을 학습시킵니다
- noise data를 m개만큼 추출합니다
- 3번 과정에서 추출한 데이터를 활용하여 생성자 모델을 학습시킵니다.
다음으로는 위의 알고리즘에 나온 GAN의 Cost function에 대해 살펴보겠습니다.
Cost Function
GAN의 Cost function은 다음과 같습니다.

판별자 모델은 각각의 데이터에 대해 알맞은 label(가상의 데이터에는 0, 실제 데이터에는 1)을 매기는 확률을 maximize시켜야 합니다. 생성자 모델은 D(G(z)), 즉 생성자가 random noise 데이터를 입력받아 생성한 가상의 데이터를 판별자 모델이 실제 데이터라고 판단할 가능성을 높혀야 합니다. 즉 1 - (D(G(z)))를 minimize시켜야 합니다. 이와 같은 minmax 형태의 cost function은 평형점을 잡기 힘들다는 문제가 있습니다. 논문에서는 이러한 문제를 해결하기 위해 생성자 모델 G를 임의의 값으로 고정합니다.
증명
이후 논문에서는 GAN 모델과 관련하여 두 가지 증명을 합니다. 첫 번째로 Cost function의 최솟값 혹은 최댓값 존재 여부, 그리고 두 번째로 극값으로 수렴 가능 여부에 대해 증명합니다(확률, 미적분, 정보이론까지 포함된 증명에 정신을 놓을 뻔 했습니다). 수식을 직접 태블릿으로 써가면서 정리해봤습니다.
- 먼저 첫 번째 증명을 위해 최적의 판별자 모델의 결과값(D)에 대한 정보가 필요합니다(논문의 Proposition 1 파트). 임의의 생성자 모델의 결과에 대해(G를 임의의 값으로 고정했을 때) 최적의 판별자 모델의 결과값은 다음과 같고, 아래와 같이 증명할 수 있습니다. C(G)는 G를 임의의 값으로 고정시켰을 때의 Cost function입니다

- 다음으로 Cost function의 전역 최솟값(global minimum) 여부에 대한 증명을 살펴보도록 하겠습니다(논문의 Theorem1 파트)
Theorem 1. The global minimum of the virtual training criterion C(G) is achieved if and only if pg = pdata. At that point, C(G) achieves the value − log 4.

생소한 Information Theory의 개념들이 등장해서 당황했습니다; 위에 나온 KL Divergence는 두 분포가 얼마나 닮은지 수치적으로 나타내는 지표입니다. 하지만 KL Divergence는 대칭(symetric)에 대해 성립하지 않습니다(p_data와 p_g의 순서가 달라질 경우 다른 값을 가집니다). 그렇기 때문에 KL-Divergence를 대칭이 되도록 보완한 Jensen-Shannon Divergence를 사용합니다.
앞서 생성자 모델은 실제 데이터의 확률 분포를 모사하는 것이라 언급했습니다. 생성자 모델이 생성한 데이터의 분포 p_g와 실제 데이터의 분포인 p_data가 같다면 Jensen-Shannon Divergence는 0의 값을 가질 것입니다. 이는 곧 두 분포가 같다면 -log4라는 전역해(global optimum)을 얻을 수 있음을 의미합니다.
- 두 번째로 전역해(global optimum)로 수렴성 여부 증명을 살펴보도록 하겠습니다.

위의 설명에서 D를 고정한 Cost function은 convex하여 수렴가능하다는 것을 알 수 있습니다. 이는 gradient descent를 통해 전역해에 수렴할 수 있음을 의미합니다.
Conclusion
이후 논문에서는 GAN 모델의 장단점과 보완할 점을 설명합니다. 논문의 저자는 GAN은 생성자 모델과 판별자 모델의 동기화(synchronization)이 잘 이뤄져야한다는 점과 생성자 모델이 생성한 가상의 데이터를 판단할 방법이 없다는 점을 단점으로 지적합니다. 하지만 학습 과정에서 Markov Chain이 없이 역전파만으로 gradient를 얻을 수 있다는 점과 추론(inference)가 필요없다는 점은 큰 이점을 가집니다.
지금까지 GAN에 대해 화폐위조범과 경찰과의 관계.. 정도밖에 이해하지 못했는데 논문을 통해 기저에 있는 작동 원리에 대해 살펴볼 수 있어 GAN에 대해 더 깊게 이해할 수 있었습니다. 수학적으로 이렇게 깊게 파고든 논문은 처음이라서 조금 어려웠지만 그만큼 더 의미 있는 논문 분석이었던 것 같습니다. 정보 이론도 조만간 조금이라도 공부해봐야겠다는 생각이 들었습니다.
Reference
GAN 논문
GAN에 대한 직관적 이해를 도와준 컬럼
GAN 수식을 이해하는데 도움을 준 Youtube 채널
GAN에 대해 진짜 자세히 설명한 블로그(강추!!!!)
KL-Divergence에 대한 설명
KL Divergence와 Jensen-Shannon Divergence에 대해 설명한 블로그
