[DL] Wide ResNet 논문 리뷰
ResNet 모델까지 딥러닝 네트워크는 주로 어떤 식으로 더 깊게 layer를 쌓을 수 있는지에 초점을 맞췄습니다. 이러한 연구 현황에서 깊이보다 네트워크의 넓이에 집중한 Wide ResNet이라는 새로운 네트워크가 등장합니다. Wide ResNet은 네트워크의 넓이를 늘림으로서 기존의 깊이 위주의 네트워크보다 더 좋은 성능을 보입니다. 그럼 Wide ResNet 논문 Wide Residual Networks을 살펴보도록 하겠습니다.
기존 ResNet의 특징과 문제점
ResNet은 지금까지 residual block에서의 activation의 위치(ReLU 함수와 Batch Normalization을 어떤 순서로 배치할지)와 네트워크를 더 깊게 할 방법에 초점을 맞춰왔습니다. 이러한 과정에서 깊이가 깊어짐에 따라 늘어나는 파라미터 수를 효과적으로 줄이기 위해 네트워크를 더 얇게(channel 수를 줄임) 만들었습니다. 심지어 Bottleneck block에 1x1 conv를 적용하면서 네트워크는 더 얇아졌습니다(1x1 conv는 channel 수를 원하는만큼 줄이는 것이 가능해 파라미터 수를 줄이는 데 사용됩니다).
ResNet의 residual block은 입력과 같은 값을 출력하는 identity mapping을 학습합니다. 하지만 gradient가 더 깊게 흐르면서 네트워크가 추가적인 학습을 하지 않을 가능성이 있습니다. Identity mapping은 이전 layer에서 배운 내용을 그대로 뒤의 layer에 전달하고 이는 오직 일부의 층만이 유용한 특징을 학습하고 대다수의 layer가 학습에 기여하는 바가 적어진다는 것을 의미합니다. 이러한 문제를 논문의 저자는 Diminishing feature reuse라고 부릅니다.
위와 같은 문제를 해결하기 위해 논문의 저자는 기존의 네트워크(ResNet)보다 더 넓은 네트워크를 설계합니다. 이같은 네트워크는 기존의 방식보다 50배 적은 layer 수를 가지지만 2배 더 빠르고 비슷하거나 더 좋은 성능을 보입니다. 이 네트워크를 Wide Residual Network라고 부릅니다. 논문에서는 ResNet을 다양하게 변형하면서 최고의 성능을 보이는 네트워크가 무엇인지 실험합니다.
실험 내용
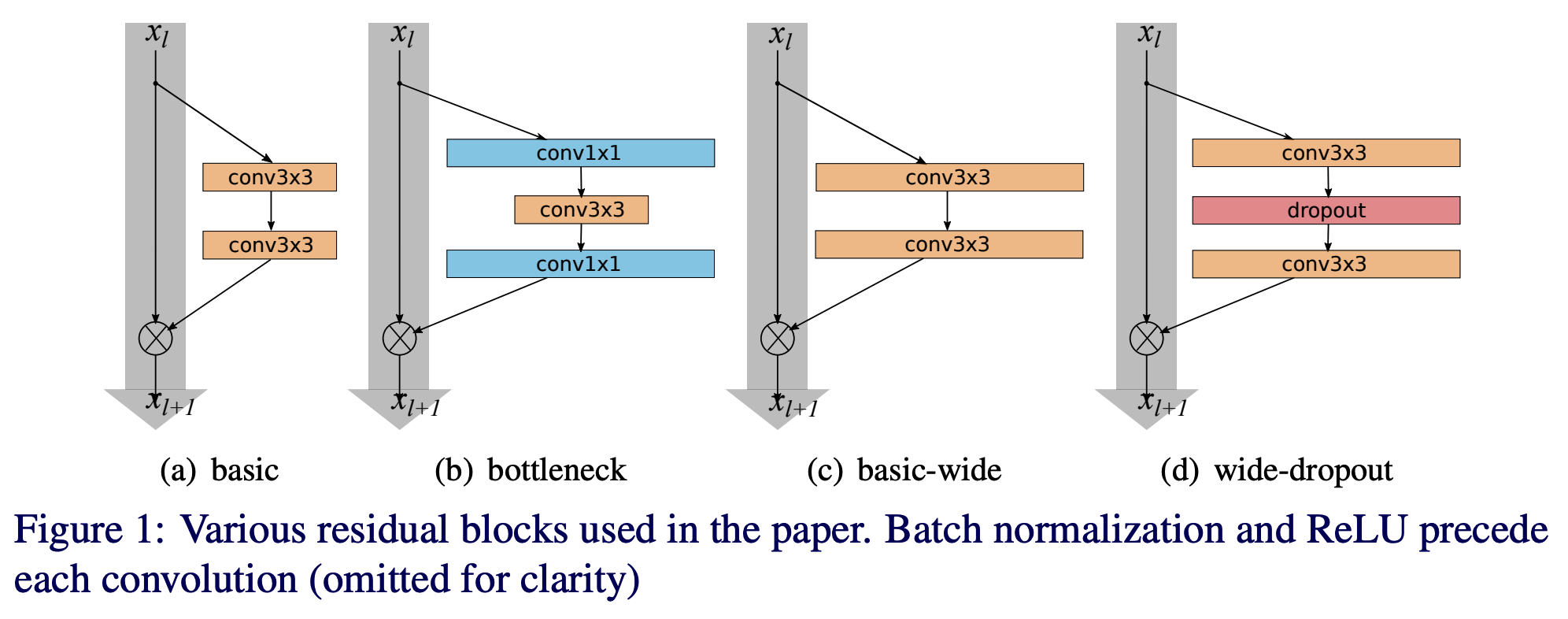
위의 그림은 논문에서 실험하는 다양한 ResNet의 변형입니다. 본격적인 실험에 앞서 논문의 저자는 고정적으로 적용할 사전 조건들을 언급합니다.
먼저 residual block에서 activation의 순서는 BN-ReLU-conv가 가장 좋은 성능을 보였기 때문에 이 순서대로 residual block을 설계한다고 하였습니다.
작은 크기의 filter가 효과적이라고 밝혀졌기 때문에 3x3 filter로 고정하였습니다.
앞으로 l은 각 block의 layer 수, k(widening factor)는 channel 수를 의미하게 됩니다.
다음으로 논문에서 실험할 사항들에 대해 살펴보도록 하겠습니다.
1) Type of convolutions in residual block
- B(3,3) - original «basic» block
- B(3,1,3) - with one extra 1×1 layer
- B(1,3,1) - with the same dimensionality of all convolutions, «straightened» bottleneck
- B(1,3) - the network has alternating 1×1 - 3×3 convolutions everywhere
- B(3,1) - similar idea to the previous block
- B(3,1,1) - Network-in-Network style block
B(a, b) (a x a) 사이즈의 conv 적용 후 (b x b) conv 적용한다는 뜻입니다. 여러 종류의 변주를 적용해보고 성능에 어떤 영향을 미치는지 알아보도록 하겠습니다. 논문에서는 위와 같이 다양한 filter size와 적용 순서와 성능과의 관계에 대한 실험을 진행합니다.
2) Number of convolutional layers per residual block 다음으로 residual block 당 conv layer의 수와 성능의 관계에 대해 실험을 진행합니다. d는 block의 총 수, l은 layer의 수를 의미합니다. l이 증가하면 d를 감소시킴으로서 네트워크 복잡도를 유지시키는 방식을 채택합니다.
3) Width of residual blocks l(layer 수), d(네트워크 내에서의 block의 총 수)와 더불어 widening factor k의 영향을 확인합니다. 앞으로 논문에서의 표기법은 다음과 같습니다.
WRN-n-k denotes a residual network that has a total number of convolutional layers n and a widening factor k
4) Dropout in residual blocks Batch Normalization을 사용하면 data augmentation을 반드시 사용해야 합니다. 하지만 논문의 저자는 이를 피하기 위해 conv layer마다 dropout을 적용하여 정규화 효과와 overfitting을 방지 효과를 얻고자 합니다. 매우 깊은 네트워크에서 dropout은 앞서 언급한 diminishing feature reuse 문제를 해결하여 각 block마다 서로 다른 feature에 대해 학습할 것이라 가정합니다.
실험 결과
1) Type of convolutions in a block 실험 결과 filter size가 달라져도 서로 비슷한 성능을 보이는 것으로 밝혀졌습니다.이후 실험의 편의성을 위해 3x3 conv만 적용하게 됩니다.
2) Number of convolutional layers per residual block l(block 당 conv layer의 수, deepening factor)의 수를 증가시키면서 성능을 확인해봤습니다. 1~4까지 l을 늘려본 결과 2가 가장 좋은 결과를 보임. 3,4는 최악의 성능을 보였는데 논문의 저자는 최적화의 난이도 증가에서 기인한다고 봅니다.
3) Width of residual blocks

widening 하이퍼 파라미터 k를 늘려가면서 실험해본 결과 성능이 향상되는 모습을 보였습니다. WRN-40-4(40층, 4width) 네트워크는 파라미터 수를 유지하면서 ResNet-1001보다 더 좋은 성능을 보였습니다. 이를 통해 서로 다른 깊이를 가진 residual 네트워크에 넓이를 늘리는 것은 성능 향상에 도움이 된다는 것을 알 수 있습니다.
파라미터 수가 너무 많아져서 정규화 효과가 필요하기 전까지는 깊이와 넓이를 늘리는 것은 성능에 도움이 됩니다. 깊은 residual network에 정규화 효과가 없는 반면 같은 파라미터 수를 가진 더 넓은 네트워크는 정규화 효과를 가져 보다 좋은 성능을 보였습니다. 실험 결과 더 넓은 네트워크는 더 깊은 네트워크보다 2배 이상의 파라미터를 학습시킬 수 있는 것으로 밝혀졌습니다. 더 깊은 네트워크는 2배 더 깊어져야만 가능하지만 이는 computation 관점에서 매우 부담될 수밖에 없습니다.
4) Dropout in residual blocks

cross-validation 을 이용해서 CIFAR 데이터에는 dropout 비율을 0.3 으로 정했습니다. 실험 결과 dropout을 적용 후 성능을 향상을 확인할 수 있었습니다.
ResNet 학습 시 첫 번째 learning rate 하락이 발생하는 순간 loss 와 validation error 가 갑자기 올라가면서 흔들리는 현상이 발생합니다. 하지만 dropout을 사용할 수 있습니다. 뿐만 아니라 dropout을 사용하면 강력한 정규화 효과를 가져와 각 layer마다 서로 다른 feature를 학습하게 됩니다.
5) ImageNet and COCO experiments

ImageNet과 COCO 데이터셋으로 성능을 측정한 결과 width 를 1.0~3.0 으로 조정해본 결과 width 가 증가하면 성능이 올라가는 것을 확인할 수 있습니다. 그리고 기존 네트워크와 비교해봤을 때 파라미터 수가 비슷하면서도 성능이 비슷하거나 더 좋은 결과를 보였습니다.
6) Computational efficiency

논문의 저자는 width를 증가시키는 방식이 균형잡힌 computational 최적화가 가능하다고 주장합니다. WRN-28-10d 네트워크, 즉 더 넓은 네트워크가 얇고 깊은 네트워크인 ResNet-1001보다 1.6배 학습이 빠르고, 심지어 WRN-40-4은 ResNet-1001과 비슷한 성능을 보이면서 8배 더 빠른 학습 속도를 보입니다.
Conclusion
- Wide ResNet 논문을 통해 네트워크 설계 시 깊이뿐만 아니라 넓이도 성능에 큰 영향을 준다는 사실을 알게 되었습니다. 딥러닝이 발전하면서 신경망 설계 시 고려해야할 점이 점점 많아지는 것 같습니다. 본 논문이 실험하는 부분만 해도 네트워크 설계 작업이 점점 복잡해지는 것이 느껴집니다. 적절한 filter size와 그 적용 순서, 적절한 깊이, 적절한 넓이 등등…
- 이후 등장하는 ResNext 논문에서는 cardianlity라는 개념을 도입하여 이러한 문제를 해결합니다. 사실 Wide ResNet 논문을 먼저 리뷰했어야야 했는데 제가 착각하고 ResNext 논문 리뷰를 먼저 해버렸습니다; ResNext 논문 역시 네트워크 설계에 대한 흥미로운 관점을 제시하니 참고하셔도 좋을 것 같습니다.
