[DL] MobileNet v1 논문 리뷰
신경망 설계 초기의 트렌드는 주로 네트워크를 더 깊고 복잡하게 만들어 더 높은 정확도를 획득하는 것이었습니다. 하지만 성능 위주의 발전 방향은 네트워크의 실행 시간이나 용량 측면에서의 효율을 의미하지는 않습니다. 현실에서는 로보틱스, 자율 주행차, AR 등의 어플리케이션은 제한된 플랫폼과 용량 내에서 주어진 시간 내에 실행되어야만 하지만 기존 네트워크는 지나치게 무겁거나 지연 시간이 걸린다는 문제가 있습니다. 이러한 문제를 해결한 MobileNet에 대해 살펴보도록 하겠습니다.
Prior Work
최근 들어 작고 효율적인 신경망을 설계하는 방식이 유행하기 시작했습니다. 주로 pretrained된 네트워크를 압축하거나, 큰 네트워크를 통해 작은 네트워크가 학습하는 distillation 방식을 주로 사용합니다. SqueezeNet처럼 bottleneck layer를 통해 효율적인 용량을 가진 모델도 등장했습니다. MobileNet은 기존 연구와 마찬가지로 네트워크의 용량을 줄이는 것은 물론 속도 측면에서도 향상된 모습을 보입니다. 이와 다르게 MobileNet은 새로운 방식의 Convolution을 적용함으로써 효율적인 네트워크를 설계했습니다.
Depthwise Seperable Convolution
기존 Convolution은 kernel filter를 적용하여 feature map을 얻고, 추출한 feature map을 결합하여 이미지의 특징을 학습합니다. MobileNet은 Depthwise Seperable Convolution을 적용하여 기존 Convolution 방식을 filtering, combining 단계로 분리시킵니다. filtering 단계에서 Depthwise Convolution을 적용하고 combining 단계에서는 Pointwise Convolution을 적용합니다.
Depthwise Convolution은 input channel 각각에 대해 한번에 하나의 kernel filter를 적용하는 연산입니다. Pointwise Convolution은 1x1 filter를 적용하여 Depthwise Convolution의 결과를 결합하는 연산입니다. 아래 그림은 일반적인 Convolution과 Depthwise Seperable Convolution을 비교합니다(D_F(input값의 width, height), M(input channel의 수), D_k(kernel filter의 크기), N(output channel의 수), D_G(feature map의 width, height))

[그림 1] Standard Convolution
일반적인 Convolution의 경우 모든 channel에 걸쳐 동일한 filter를 적용하고, 얻은 결과를 더해주는 과정을 거칩니다. 이는 일반적인 Convolution은 input channel의 영향을 받는다는 것을 의미합니다. 연산량 : (D_G) x (D_G) x (D_K) x (D_K) x (M) x (N)

[그림 2] Depthwise Convolution
Depthwise Convolution은 input channel과 같은 수만큼의 output channel을 가지도록 설정하고 각각의 channel에 대해 하나의 filter를 적용시켜줍니다. channel별로 독립적으로 convolution을 적용하기 때문에 연산량에 input channel의 수가 포함되지 않습니다. 연산량 : (D_F) x (D_F) x (D_K) x (D_K) x (M)

[그림 3] Pointwise Convolution
Pointwise Convolution은 1x1 filter를 적용하여 channel 수를 자유롭게 조정하여 N개 만큼 feature map을 생성해줍니다. 연산량 : (D_G) x (D_G) x (M) x (N)
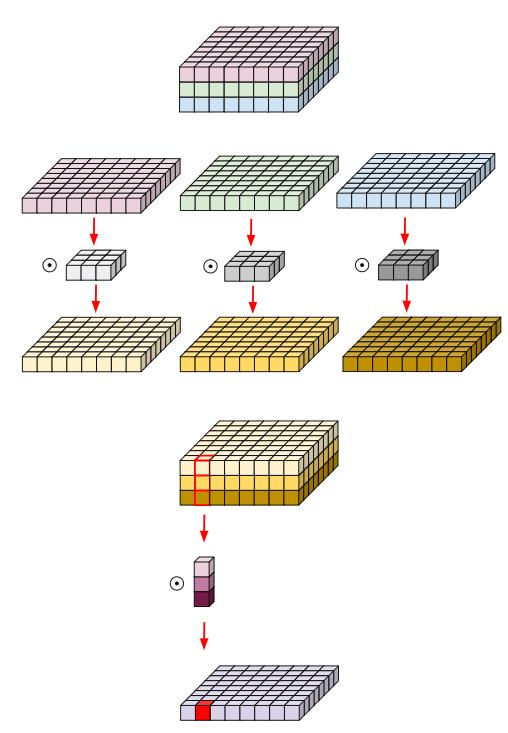
[그림 4] Depthwise Seperable Convolution
Depthwise Seperable Convolution은 Depthwise Convolution과 Pointwise Convolution을 순차적으로 적용한 결과이므로 연산량은 두 Convolution의 연산량의 합과 같습니다. 연산량 : {(D_F) x (D_F) x (D_K) x (D_K) x (M)} + {(D_G) x (D_G) x (M) x (N)}
비교해보면 기존 Convolution보다 Depthwise Seperable Convolution이 연산량이 8~9배 정도 적다는 것을 확인할 수 있습니다. 마찬가지로 필요한 파라미터의 수도 크게 줄어 용량 측면에도 효율적인 모습을 보입니다. 그럼에도 성능은 기존 모델보다 약간 낮은 정도를 보입니다.
Network Structure
다음으로 네트워크의 세부 구조에 대해 살펴보도록 하겠습니다.

- 마지막 layer를 제외하고 모든 layer에 Batch Normalization과 ReLU를 적용합니다.
- Downsampling은 적절한 stride를 지정하여 실행하였습니다
- Depthwise Convolution과 Pointwise Convolution을 별개로 봤을 때 MobileNet은 총 28개의 layer를 가집니다.
- MobileNet은 95%의 연산을 1x1 conv를 하는데 사용하며, 75%의 파라미터가 이에 해당합니다. 대부분의 추가적인 파라미터는 마지막 layer인 Fully Connected layer에 있습니다.
- MobileNet은 작은 네트워크로 overfitting의 문제가 많지 않아 regularization과 data augmentation을 상대적으로 적게 적용했습니다
- 모델의 크기가 작기 때문에 weight decay도 적용하지 않았습니다.
Hyperparamters
MobileNet은 더 작고 빠른 모델을 설계하기 위해 2개의 하이퍼파라미터를 도입합니다.
Width multiplier alpha는 각 layer를 얇게 만드는 하이퍼 파라미터입니다. input channel M과 output channel N에 Width multiplier를 곱해줘 channel의 수를 줄여줍니다. alpha는 1 이하의 값을 가지고 alpha를 1 미만으로 설정할 경우 reduced MobileNet이라고 부릅니다.
Resolution multiplier gamma는 input값의 width, height의 크기를 줄여주는 역할을 합니다. gamma 역시 1 이하의 값을 가집니다.
두 하이퍼 파라미터를 적용함으로써 더 얇고 작은 네트워크를 설계하는 것이 가능합니다. 하지만 이로 인해 어느 정도 성능 하락이 발생할 수밖에 없습니다. 논문에서는 성능과 computational cost 사이의 관계에 대해 다양한 실험을 통해 탐색합니다.
Experiments
일반적인 Convolution을 적용한 모델과 Depthwise Seperable Convolution을 적용한 MobileNet이 용량과 속도 측면에서 크게 앞선 결과를 확인할 수 있었습니다. 성능은 오직 1% 정도 하락한 모습을 보였습니다.
비슷한 파라미터 수와 연산량을 가지도록 한 후 다양한 실험을 진행한 결과 MobileNet은 가늘게 설계했을 때가 얇게 설계했을 때 보다 3% 가량 좋은 성능을 보였습니다.
정확도는 alpha가 0.25로 설정되기 전까지 서서히 감소하는 모습을 보였습니다. Resolution multiplier의 경우 마찬가지입니다.
MobileNet은 VGG보다 32배 작고 27배 정도 연산량이 적으며 정확도는 비슷한 결과를 보였습니다. GoogLeNet과 비교했을 때 정확도는 비슷하지만 용량이 더 작으며 2.5배 연산량이 적습니다. reduced MobileNet(alpha=0.5, resolution=160)의 경우 AlexNet보다 4% 더 높은 정확도를 보이며 45배 더 작고 9.4배 이하의 연산량을 가집니다. 또한 SqueezeNet보다 4% 더 높은 정확도를 보이고 비슷한 사이즈에 22배 이상의 연산량 절약 효과를 보입니다.
Conclusion
논문에서는 MobileNet이 Object Detection, Face Attribute classification, large scale geolocalization 등 다양한 분야에 적용될 수 있음을 보이며 마무리됩니다. 다른 부분보다 Depthwise Seperable Convolution을 이해하기 어려워 읽는데 오래 걸렸던 것 같습니다. 아이폰에서 Tensorflow Lite를 통해 MobileNet을 실행할 수 있다고 하니, 시간 있을 때 모바일 환경에서 어플리케이션을 구현해볼 예정입니다.
Reference
MobileNet 논문
CodeEmporium님이 설명한 Depthwise Seperable Convolution 영상(매우 유용함!)
Depthwise Seperable Convolution을 설명한 블로그
