[DL] SPPNet 논문 리뷰
RCNN은 Object detection에 딥러닝을 적용하면서 기존 방식보다 성능 면에서 월등한 결과를 보였습니다. 그럼에도 불구하고 inference와 학습 시 지나지게 많은 시간을 소요한다는 단점을 가지고 있습니다. 이번 포스팅에서는 RCNN이 가지는 문제를 해결하고 이후 등장하는 Fast RCNN 모델에 큰 영향을 끼친 SPPNet에 대해 살펴보도록 하겠습니다.
What’s the Problem?
1) 고정된 크기의 입력 이미지
현재 CNN 모델은 학습 시 고정된 크기의 이미지를 입력받고, 이를 위해 입력 이미지를 고정된 크기로 crop하거나 warp시키는 것이 일반적입니다. 하지만 crop된 이미지는 객체에 대한 전체 정보를 포함하지 못할 수도 있으며, warp된 이미지는 공간적으로 왜곡되어 인식 성능이 하락할 수 있습니다. 이러한 이유로 입력 이미지의 크기를 고정시키지 않는 것이 바람직하지만 CNN 네트워크 하단에 있는 fully connected layer 때문에 다양한 크기의 이미지를 입력받는 것은 불가능합니다.

[그림 1] 입력 이미지의 크기에 따른 파라미터 수의 차이
conv layer는 오직 kernel(3x3, 5x5 filters etc)만 학습시키기 때문에 입력 이미지의 크기와 무관하게 항상 같은 양의 weight을 학습시킵니다. 하지만 fc layer는 입력 이미지 크기에 맞게 weight를 학습시키기 때문에 입력 이미지의 크기에 영향을 받습니다. 학습은 같은 weight에 대해 여러 차례 수행되기 때문에 입력 이미지가 달라지면 학습 하는 weight의 수도 달라지는 것을 의미합니다.
2) RCNN의 수행 속도
RCNN은 학습과 inference 시 수행 속도가 매우 느리다는 단점이 있습니다. 2000여개의 후보 영역을 뽑고, warp시키고 이에 대해 개별적으로 feature를 추출하다보니 시간이 오래 걸릴 수밖에 없습니다.
Spatial Pyramid Pooling(SPP) layer
SPPNet은 앞서 언급한 네트워크의 고정된 크기의 입력 이미지에 대한 제약을 없애기 위해 Spatial pyramid pooling(SPP) layer라는 새로운 아이디어를 제시합니다. SPP layer는 서로 다른 크기의 입력 데이터를 같은 크기를 가진 벡터로 반환해주는 pooling layer입니다.

[그림 2] Spatial Pyramid Pooling layer
위의 그림을 보면 일반적인 CNN 네트워크는 서로 다른 크기를 가진 입력 이미지를 crop 혹인 warp시키고, 이를 네트워크에 통과시켜 feature를 추출합니다. 반면에 SPPNet은 원본 이미지를 조작하지 않고 그대로 네트워크에 통과시킨 후 SPP layer를 거쳐 동일한 크기의 벡터로 변환됩니다. 이후 두 모델 모두 fc layer를 거치게 됩니다.
SPP layer은 feature map을 일정 구획으로 나눠 각 구획별로 max pooling 함으로서 다양한 크기의 입력 데이터를 동일한 크기로 가진 출력값으로 변환합니다. 사실 논문 자체에는 SPP layer에 대해 구체적으로 언급되지 않아 별도로 찾아본 결과 Spatial Pyramid Matching 를 적용한 것을 알게 되었습니다.

[그림 3] Spatial Pyramid Matching
위의 그림에서 볼 수 있듯이 단일 이미지를 여러 level에 걸쳐 서로 다른 크기로 분할합니다. level0은 원본 이미지에서 각 요소의 개수를 벡터의 요소로 가집니다. level1 에서는 이미지를 4분할 하여 구획마다 각 요소의 개수를 벡터의 요소로 가집니다. level 2에서는 이미지를 16분할 하여 마찬가지의 방식으로 진행합니다. 논문에서는 level을 높혀가며 실험한 결과 single level보다 multi level(6, 3, 2, 1 총 50개의 bin)을 적용한 경우가 성능 면에서 더 좋은 결과를 보였다고 합니다.

[그림 4] SPP layer의 작동 방식
이를 CNN 네트워크에 추가함으로서 네트워크는 이미지의 crop/warp 등으로 인한 정보 손실을 최소화하고 고정된 크기의 벡터를 fc layer에 전달하는 것이 가능해집니다. SPP layer는 마지막 conv layer 뒤에 위치시킵니다(마지막 max pooling을 제외시킵니다). 최종적으로 fc layer는 kM 크기의 벡터를 입력받습니다. 여기서 k는 마지막 conv layer의 feature map 수(위의 그림에서 256)를 의미하고 M은 bin, 즉 구간의 수(위의 그림에서 1 + 4 + 16)를 의미합니다.
Model Architecture

[그림 5] SPPNet 구조
1) Selective Search fast mode를 사용하여 이미지 한 장 당 2000개의 후보 영역을 생성합니다.
2) 원본 이미지를 CNN에 넣어 feature map을 얻습니다. feature map에 후보 영역을 투영 시킨 후 SPP layer에 전달합니다.
3) SPP layer에서는 4-level 로(1,2,3,6, 총 50 bins)를 사용하여 길이가 12800(256 * 50) 인 벡터가 하나의 후보 영역에서 나오게 됩니다. 이 벡터를 fc layer에 전달합니다.
4) 이후 나온 결과를 SVM 분류기에 넣어 범주가 분류합니다. 동시에 Bounding box Regression도 진행합니다.
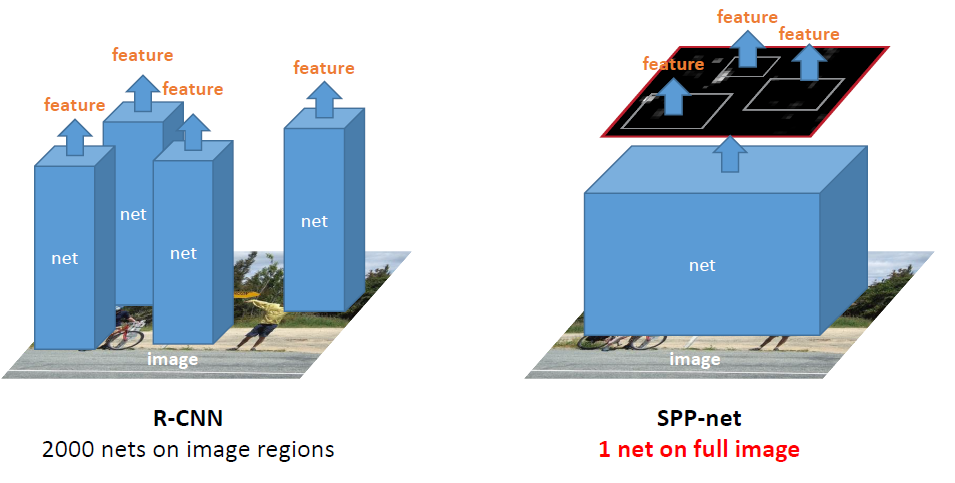
[그림 6] RCNN과 SPPNet의 차이
RCNN은 후보 영역을 추출하고 개별적으로 학습하는 과정이 가장 큰 병목의 원인입니다. 이미지 한 장 당 2000개의 region을 추출하고 2000개의 후보영역 하나하나에 대해서 feature 추출하는 작업은 오래 걸릴 수밖에 없습니다. 이에 반해 SPPNet은 원본 이미지 한 장만 CNN을 거치고, 이를 통해 feature를 추출하고 feature map에 대해서 pooling을 적용합니다. feature map으로부터 bounding box가 있는 위치에 feature를 추출하기 때문에 학습 및 inference 시간을 크게 절약할 수 있습니다.
Performance

[그림 7] RCNN과 SPPNet의 실행 속도 차이
SPPNet은 Object detection 시 pre-trained 모델을 사용한 결과 R-CNN보다 100배 이상 빠른 속도를 보였습니다. mAP값은 59.2%로, 58.5%가 나온 R-CNN보다 더 높게 나왔습니다.
Conclusion
SPPNet은 기존의 Spatial Pyramid Matching 기법을 적용하여 학습 및 inference 시간을 크게 감소시켰습니다. SPP layer의 작동원리에 대해 설명하는 부분이 빈약하여 직접 그림까지 그려가면서 공부했습니다. feature map에서 고정된 크기의 벡터로 변환되기까지 크기를 추적하는 과정이 큰 의미가 있었던 것 같습니다. 다음 포스팅에서는 SPPNet의 영향을 받아 만들어진 Fast RCNN에 대해 살펴보도록 하겠습니다.
