[DL] SSD 논문 리뷰
이번 포스팅에서는 최초의 실시간 객체 탐지 모델인 SSD(Single Shot MultiBox Detector)에 대해 살펴보도록 하겠습니다. SSD모델은 bounding box proposal 과정을 제거하고, 뒤따라오는 feature 추출 과정을 제거함으로서 속도 면에서 개선을 이뤄냈습니다.
What’s the problem?
Faster R-CNN과 같은 객체 탐지 기법은 성능은 좋으나 임베디드 시스템이나 모바일 기기에서 computationally expensive하며 실시간 객체 탐지에 너무 느리다는 단점이 있습니다. Faster R-CNN은 7SPF(Second Per Frame, 초당 프레임 수) 정도만 나와 실시간 객체 탐지에 부적합합니다.
YOLO v1은 하나의 grid에 하나의 bounding box만을 예측하기 때문에 grid 내 존재하는 여러 개의 작은 객체를 탐지할 수 없습니다.
Improvements
Multi-scale feature maps for detection

[그림 1] YOLO v1 vs SSD 비교
YOLO v1은 원본 이미지를 7x7 크기의 grid로 나눠 각 grid별로 하나의 bounding box를 예측하는 반면, SSD는 다양한 크기의 다수의 feature map으로부터 다양한 크기의 다수의 bounding box를 예측합니다.
[그림 2] SSD model architecture
SSD는 VGG base model를 기반으로 conv layer를 순차적으로 추가합니다. 순차적으로 추가된 layer를 통해 얻어진 feature map을 기반으로 bounding box를 예측합니다. 위의 그림을 보면 layer를 거칠 때마다 서로 다른 크기의 feature map을 얻어 총 6개의 scale(38x38, 19x19, 10x10, 5x5, 3x3, 1x1)의 feature map을 기반으로 객체 탐지를 진행합니다.
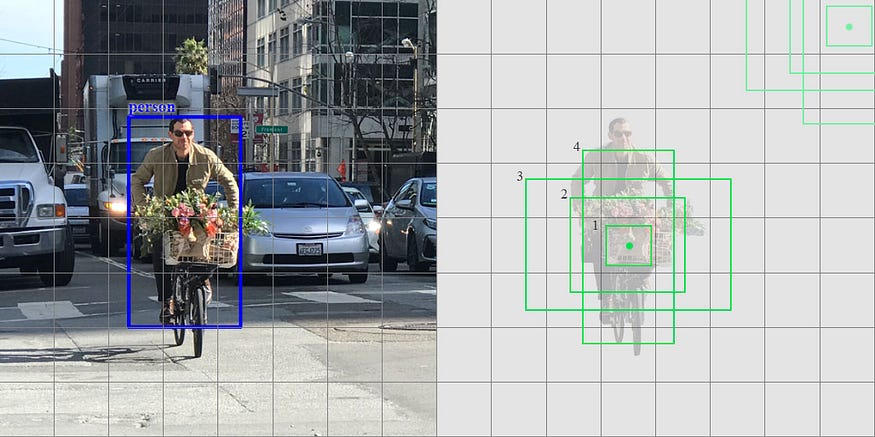
Default boxes and aspect ratios
 </img>
</img>
[그림 3] feature map의 크기에 따른 default box
앞서 언급했다시피 SSD는 feature map의 cell마다 여러 개의 bounding box를 예측합니다. 이 때 사용되는 예측하는 bounding box는 다양한 scale과 ratio를 가지고, 논문에서는 이를 default box라고 부릅니다. 각 feature map의 cell마다 default box의 좌표(shape offset)와 범주별 confidence score를 예측합니다. 만약 m x n 크기의 feature map에 대해서 c개의 범주(class)에 대해 k개의 default box를 예측한다면 총 (c+4)kmn 크기의 결과가 산출됩니다.
default box는 Faster R-CNN 모델에서 사용된 anchor box와 유사합니다. 하지만 서로 다른 크기의 box들이, 서로 다른 크기의 feature map에 적용된다는 점에서 차이가 있습니다. 이를 통해서 산출될 수 있는 box들이 겹치는 영역이 최소화(discretize)됩니다.
Model Architecture
Matching strategy
학습 시 어떤 default box가 ground truth와 일치하는지 결정하고, 그에 따라 네트워크를 학습시켜야 합니다. 이를 위해 우선 Jaccard overlap이 가장 높은 default box와 ground truth를 matching시키는 작업부터 합니다.
이 때 하나의 jaccard overlap이 가장 높은 하나의 default box를 ground truth에 매칭시키는 것이 아니라 threshold(=0.5)보다 높은 모든 default box를 매칭시킵니다.이를 통해 네트워크는 가장 높은 overlap을 가진 box 하나만을 예측하는 것이 아니라높은 점수를 가지는 여러 개의 default box를 예측하는 방식을 학습하게 됩니다.
Training Objective
모델 학습을 위한 loss function은 아래와 같습니다.
 </img>
</img>
[그림 4] 전체 loss function
- 전체 loss function은 Class loss와 bounding box loss의 합입니다.
- 두 loss 사이의 가중치는 alpha를 통해 조정하고,
- 전체 loss 정규화를 위해 matching된 bounding box의 수 N으로 나눠줍니다.
 </img>
</img>
[그림 5] bounding box loss function
- bounding box loss function은 Smooth L1 loss를 사용합니다.
- indicator parameter는 default box와 ground truth box의 IoU가 0.5 이상일 경우 1, 이하일 경우 0을 반환합니다. 즉 matching된 default box에 대해서만 loss를 구합니다.
- ground truth box를 구하는 과정은 R-CNN 계열 모델의 방식과 같습니다.
 </img>
</img>
[그림 6] class loss function
- class loss는 i번째 default box와 j번째 ground truth box의 IoU가 0.5 이상인 Positive class인 경우 softmax loss function을 사용합니다.
- 그 외의 negative class, 즉 범주에 소속되는 객체가 아닌 배경일 경우 0을 반환합니다.
Choosing scales and aspect ratios for default boxes
</img>
[그림 7] default boxes
SSD 모델은 서로 다른 크기와 aspect ratio과 scale의 default box를 서로 다른 크기의 feature map에 적용하여 다양한 예측 결과를 얻을 수 있다. 이를 통해 객체의 다양한 크기와 모양을 포착하는 것이 가능합니다. 위의 그림에서 4x4 크기의 feature map에서는 개가 포착되지만 8x8 크기의 feature map에서는 개가 포착되지 않습니다. 이는 더 얕은 layer는 더 작은 객체를 찾을 수 있음을 의미합니다.
 </img>
</img>
[그림 8] default box scale and ratio
위의 수식을 통해 총 6개의 서로 다른 scale과 aspect ratio의 default box를 구할 수 있습니다. aspect ratio가 1인 경우 s_k x s_(k+1)를 추가적으로 구해, 2개의 default box가 생깁니다.
Hard Negative mining
matching 작업 후 대부분의 default box는 negative class에 속합니다. 원본 이미지 내 객체가 얼마 없기 때문에 대부분의 default box는 배경이기 때문입니다. 이로 인해 positive와 negative 훈련 샘플 중 심각한 불균형한 문제가 발생합니다. 이를 해결하기 위해 논문의 저자는 모든 negative sample을 사용하는 것이 아니라 가장 높은 confidence loss를 가진 default box를 뽑아 positive class와 negative class의 비율이 3:1이 되도록 했습니다. 이를 통해 더 빠른 최적화와 안정적인 학습이 가능하게 됩니다.
Data Augmentation
Data augmentation은
- 원본 이미지 전체를 사용했습니다.
- 객체와 최소 jaccard overlap이 0.1, 0.3, 0.5, 0.7, 0.9가 되도록 patch를 sample했습니다
- random sampling하여 patch를 구했습니다.
Experiments
마지막으로 논문의 저자가 실험한 내용들에 대해 살펴보도록 하겠습니다.
작은 이미지보다 큰 이미지를 사용했을 때 성능이 더 좋았다고 합니다(300x300보다 512x512가 성능이 더 좋음). 더 작은 이미지의 경우 낮은 layer에서 특징을 포착하지 못할 수 있기 때문입니다.
다양한 크기의 default box가 좋음. 4개의 ratio만 사용할 경우 0.6%의 성능 하락하였습니다
data augmentation를 적용했을 시 8.8% 성능 향상이 있었습니다.
SSD의 가장 큰 기여는 서로 다른 크기의 output layer의 feautre map에 서로 다른 크기와 ratio의 default box를 사요했다는 점입니다. default box의 수를 8732로 고정한 채로 output layer를 줄여나가자 accuracy가 점점 떨어지는 결과를 보였습니다.
Faster R-CNN보다 정확도와 inference 속도 측면에서 더 월등한 모습을 보였습니다. SSD300(300x300)은 최초의 실시간 객체 탐지 방식 중 처음으로 70% 이상의 mAP값을 얻었습니다.
Conclusion
SSD는 region proposal 과정을 생략하여 학습 및 inference 속도를 향상시켰으며, 다양한 크기의 feature map에 대한 다양한 크기와 비율의 bounding box를 적용하여 객체 인식률을 높혔습니다. YOLO의 다음 후속 버전은 SSD의 모델 구조를 참고하여 성능을 개선합니다. 다음 포스팅에서는 YOLO의 개선된 버전을 살펴보도록 하겠습니다.
Reference
SSD 논문
SSD loss 부분에 대해 잘 설명한 블로그
default box 시각화를 잘 해준 블로그
모델 학습 과정을 잘 설명한 ppt
