[Kaggle] Pseudo Labeling
최근 kaggle 대회 참가를 준비하면서 성능을 향상시키기 위한 다양한 머신러닝 학습 방법을 알게 되었습니다. 오늘 포스팅에서는 그 중에서도 가장 직관적이지만 좋은 결과를 보여주었던 Pseudo Labeling에 대해 살펴보고자 합니다.
What?


[그림 1] pseudo labeling 학습 과정
Pseudo labeling 은 적은 수의 labeled 데이터와 많은 수의 labeled 되지 않은 데이터를 활용하여 모델의 성능을 향상시키는 방법입니다. unlabeld data를 사용할 때 모델이 더 많은 케이스의 데이터를 고려하기 때문에 overfitting에 강건해집니다. Kaggle competition에서는 public ranking에 비해 private ranking이 크게 떨어지는 shakeup을 방지하는 데 좋은 방법으로 사용될 수 있습니다.
How?
Training Process
pseudo labeling을 시행하는 방법은 다음과 같습니다.
1) labeled 데이터를 사용하여 모델을 학습시킵니다
2) 학습된 모델을 사용하여 unlabeld 데이터를 예측하여 그 결과를 label로 사용하여 unlabeled 데이터를 pseudo labeled 데이터로 만듭니다.
3) labeled data와 pseudo labeled 데이터를 모두 사용하여 모델을 학습시킵니다.
4) label 데이터의 loss와 unlabeled 데이터의 loss를 합쳐 역전파를 진행합니다.
Loss function
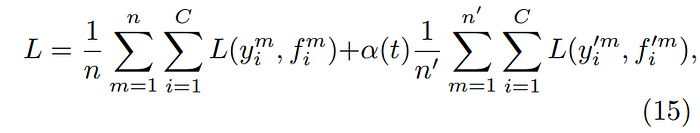
[그림 2] pseudo labeling loss function
위의 loss function 수식에서 첫 항은 labeled loss를 의미합니다. 즉 과정 1)에서 labeld 데이터를 통해 모델을 학습시켰을 시 발생하는 loss입니다.
두번 째 항은 labeled 데이터와 pseudo labeled 데이터를 모두 사용하여 학습시켰을 시 발생하는 loss입니다.
alpha값은 전체 loss에서 unlabeled data를 사용할 때의 기여분을 조정하는 하이퍼 파라미터입니다. 이 하이퍼 파라미터를 사용하여 모델이 labeled 데이터에 좀 더 집중하여 성능을 끌어올릴 수 있습니다. 이후 가중치를 높혀 모델이 unlabeled loss를 좀 더 집중하도록 조정할 수 있습니다. alpha값은 아래와 같은 방식으로 조정합니다.
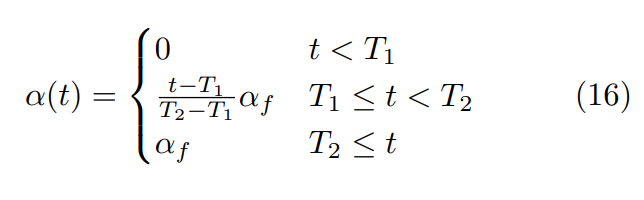
[그림 3] epoch에 따른 alpha값 변화
논문에서 T1=100, T2=600으로 지정했으며, 이를 통해 모델은 unlabeled 데이터를 천천히 통합시키는 것이 가능합니다. alpha를 통해 점진적으로 unlabeled data를 학습하는 비율을 늘려 local minima에 빠지는 문제를 어느 정도 해결해줍니다.
Why not?
하지만 이같은 pseudo labeling이 좋은 결과를 가져오지 못하는 경우가 있습니다.
labeled data의 수가 지나치게 적은 경우 pseudo labeling은 좋은 성능을 내지 못합니다. 데이터의 구조를 제대로 학습하지 못하면서 pseudo labeled data를 만드는 과정에서 잘못된 추론을 진행할 수 있기 때문입니다. 또한 데이터 수가 적기 때문에 outlier에 민감하다는 단점도 있습니다.
간혹 labeled data를 통해 학습을 진행할 때 전체 범주에 대해 학습하지 못하는 경우, 모델의 성능이 떨어질 수 있습니다. 모든 범주에 대한 학습을 진행하지 않았기 때문에 학습하지 않은 범주에 대한 추론이 제대로 이뤄지기 힘들기 때문입니다.
Conclusion
Pseudo labeling은 labeled data를 학습하면서 데이터에 내재된 cluster 구조를 학습합니다. 이를 통해 unlabeled data에 대해 추론하여 pseudo labeled data를 만들고 이를 학습에 추가합니다. 이러한 과정을 통해 모델은 보다 overfitting에 강건해집니다. 딥러닝을 이론적으로만 공부하다가 kaggle과 같은 실제 대회를 보면서 유용한 최신 기법들에 대해 알게 되었고 pseudo labeling도 그 중 하나입니다. 앞으로도 kaggle에서 배운 유용한 머신러닝 학습 기법들에 대해 포스팅하겠습니다.
Reference
pseudo labeling 논문을 잘 정리한 블로그
TSNE를 통해 pseudo labeling 성능을 잘 보여준 블로그
pseudo labeling을 가볍게 구현한 코드
kaggle Global Wheat Detection 대회에서 pseudo labeling을 적용한 notebook
