[DL] EfficientNet 논문 리뷰
지금까지 20편이 넘는 컴퓨터 비전 분야 딥러닝 논문들을 읽어오면서 CNN 모델 구조의 흐름을 알게 되었습니다. 처음에는 더 깊은 모델을 추구하였으며, 이후에는 더 넓은 모델, 보다 최근에는 더 가벼운 모델을 설계하는 방향으로 연구의 흐름이 진행되었습니다. 하지만 더 깊고, 더 넓으며, (제가 읽은 논문 중에는 없었지만)더 높은 이미지 해상도를 입력값으로 가지는 동시에 더 가벼운 방향으로 모델 설계를 고려한 경우는 없었습니다. 오늘 포스팅에서는 앞서 언급한 모델의 속성을 모두 추구한 EfficientNet모델에 대해 살펴보도록 하겠습니다. 현재 ImageNet Dataset 분류 성능 랭킹에서 최상위권은 모두 EfficientNet의 변주 모델이 차지하고 있을 정도로 좋은 성능을 보이고 있습니다.
What’s the Problem?
기존 ConvNet 모델은 깊이를 늘리거나(depth scaling), 넓이를 늘리거나(width scaling), 네트워크가 입력으로 받는 이미지의 해상도를 늘리는(resolution scaling) 방식을 통해 성능을 향상시켜왔습니다. ResNet은 skip connection을 통해 깊이를 늘린 모델이며, ResNext, Wide ResNet은 각각 channel, cardinality 조정을 통해 넓이를 늘린 모델입니다. 논문의 저자는 기존 ConvNet 모델이 성능을 향상시키기 위해 임의로 모델의 크기(Scale)를 키운다는 점을 지적했습니다. 또한 이러한 모델 설계 방식은 모델의 크기가 커지면 필연적으로 파라미터 수가 많아진다는 단점이 있습니다.

[그림 1] Compound Scaling
여기서 논문의 저자는 ConvNet을 scaling up하는 방식에 대해 다시 생각합니다.
Is there a principled method to scale up ConvNets that can achieve better accuracy and efficiency?

[그림 2] accuracy와 파라미터 수에서 좋은 성능을 보이는 EfficientNet
즉 논문의 저자는 정확도와 효율성 모두를 얻으면서 CNN 모델의 크기를 키울 수 있는 근본적인 방식에 대해 강구합니다. 이를 구현하기 위해 논문의 저자는 네트워크의 넓이(width), 깊이(depth), 그리고 이미지의 해상도(resolution)를 여러 개의 고정된 계수로 지정하여 모델의 크기를 조정하는 Compound Scaling 방식을 고안합니다.
Improvements
Problem Formulation

[그림 3] Optimization Problem
논문의 저자는 최적의 모델 구조를 설계하기 위한 문제를 위와 같이 정의합니다. N은 전체 네트어크를 의미하며 d, w, r은 각각 모델의 크기를 조정하는 깊이, 넓이, 해상도 scaling factor입니다(F는 하나의 layer라고 이해하면 되고, X는 입력값입니다).즉 논문에서 구하고자 하는 최적의 모델은 모델의 accuracy를 최대로 하는 동시에, target memory보다 작거나 같게, FLOPS 역시 target flops보다 작거나 같은 모델인 것입니다.
Scaling Dimensions
최적의 scaling factor(d, w, r)는 서로의 영향을 받고 서로 다른 자원의 제약 아래서 값이 변경된다는 어려움이 있습니다. 이를 해결하기 위해 baseline 모델에서 다른 파라미터를 고정한 채, 서로 다른 scaling factor를 조정하여 accuracy를 측정해보았습니다.

[그림 4] Scaling factor 조정에 따른 accuracy 변화
모델의 depth는 가장 흔하게 사용되는 방식이며, 모델의 깊이가 깊어질수록 더 복잡하고 풍족한 특징을 학습하며, 일반화를 잘 한다는 장점이 있습니다. 하지만 vanishing gradient 문제에 취약하며, 이를 해결하기 위해 여러 방법들이 도입되었지만(batch normalization, skip connection) accuracy 상승폭이 점점 하락한다는 근본적이 문제가 있습니다. baseline 모델 역시 d를 늘려도 accuracy 상승폭이 점차 줄어드는 모습을 보였습니다.
모델의 width 조정은 흔히 작은 모델에 많이 사용됩니다. 더 넓은 모델은 더 세밀한 특징을 포착하며, 학습하기 쉽다는 장점이 있습니다. 하지만 넓지만 얕은 모델은 고수준의 특징을 학습하는 데 어려움을 겪는다는 문제가 있습니다. baseline 모델에서 w를 늘려도 accuracy가 쉽게 포화된다는 문제가 발견되었습니다.
입력 이미지의 resolution이 높은 모델은 더 세밀한 특징을 학습한다는 장점이 있습니다. 하지만 baselien 모델을 통해 실험한 결과, r을 높히면 accuracy가 상승하지만 쉽게 포화된다는 문제가 있습니다.
네트워크의 scaling factor(depth, width, resolution)를 조정하면 accuracy가 상승하지만, 상승폭이 쉽게 하락하는 결과를 보입니다.
Compound Scaling
위의 실험 결과 각 scaling factor가 서로 독립적이지 않다는 것을 확인할 수 있습니다. 또한 더 높은 해상도의 이미지를 입력값으로 받을 경우, 더 큰 receptive field를 확보하기 위해 네트워크의 깊이와 넓이를 증가시켜야 합니다. 해상도가 높은 이미지의 경우 receptive field가 클 경우 더 세심한 특징과 더 많은 픽셀을 포착하는데 도움이 되기 때문입니다. 이를 통해 하나의 scaling factor만 조정(single-dimension scaling)하는 것이 아니라 서로 다른 scaling factor를 조정하는 방식을 채택하게 되었습니다.
더 높은 accuracy와 효율성을 위해서 네트워크의 모든 scaling factor를 조정할 필요가 있습니다
논문의 저자는 Compound Scaling 방식을 제시합니다. 아래와 같은 수식을 통해 최적의 scaling factor를 찾습니다.

[그림 5] Compound Scaling
알파, 베타, 감마는 각각 네트워크의 depth, width, resolution에 얼마만큼의 자원을 할당할지를 결정하는 파라미터이며, 작은 grid search를 통해 얻습니다. coefficient 값은 실험자가 지정하는 하이퍼 파라미터로 사용할 수 있는 자원에 따라 수를 조정합니다. 아래의 식에서 베타와 감마에 제곱이 있는 이유는 depth가 2배가 되면 FLOPS는 2배로 느는 반면, width, resolution이 2배가 되면 FLOPS는 4배가 되기 때문입니다.
Model Architecture
baseline 모델이 어느 정도 성능을 보장해야 기본적인 성능을 보장받을 수 있기 때문에 좋은 baseline 모델을 설계하는 것을 중요합니다. 논문의 저자는 MNasNet 모델에서 사용되었던 최적화 방식을 통해 baseline 모델을 설계합니다. \[ACC(m)\times[FLOPS(m)/T]^{w}\]
위의 수식을 통해 모델의 accuracy와 FLOPS를 모두 고려하였습니다. 논문에서는 지연 시간(latency) 대신에 FLOPS를 최적화했다고 합니다. 이렇게 설계한 모델을 EfficientNet-B0이라고 부릅니다.
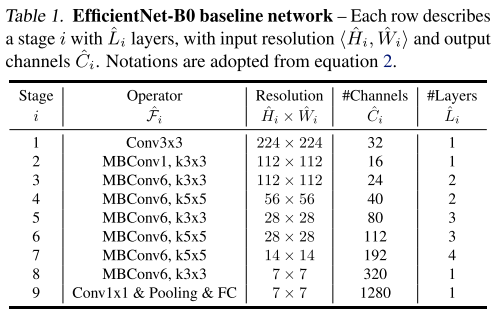
[그림 6] EfficientNet-B0 baseline network
EfficientNet-B0에서 시작하여 모델의 아래와 같은 단계에 따라 크기를 키웁니다.
step 1 coefficient의 크기를 1로 고정하고 2배 더 많은 자원이 사용가능하다고 가정하고 알파, 베타 감마 값을 grid search를 통해 찾습니다. 논문의 저자는 EfficientNet-B0의 경우 알파가 1.2, 베타는 1.1, 감마는 1.15일 때 가장 좋은 결과가 나왔다고 합니다.
step 2 알파, 베타, 감마 ㄱ밧을 고정하고 coefficient 값을 조정하여 모델의 크기를 키워 EfficientNet-B1 ~B7까지의 결과를 얻습니다.
크기가 큰 모델에 대해 grid search를 적용하면 너무 많은 탐색 시간이 걸리기 때문에 step 1 과정을 작은 모델을 통해 진행하였으며 step 2 과정은 큰 모델을 통해 수행하였다고 합니다.
Experiments

[그림 7] EfficientNet-B0 baseline network
논문의 저자는 scaling 방식을 서로 다른 모델에 적용하여 ImageNet 데이터셋을 통해 정확도, 파라미터 수, FLOPS를 측정했습니다. 위의 그림에서 볼 수 있듯이 EfficientNet 계열의 모델이 가장 좋은 성능을 보이고 있습니다,
EfficientNet-B7의 경우 top1 accuracy가 84.4%, top5 accuracy는 97.1%라는 높은 수치를 보입니다. 파라미터 수는 6600만 개, FLOPS는 37B 값을 가지며 GPipe보다 더 정확하지만 8.4배 더 작은 동시에 6.1배 이상 빠릅니다 .
- 또한 EfficientNet-B3의 경우 ResNext-101 모델보다 더 높은 정확도를 가지면서 18배 적은 FLOPS 값을 보입니다.
EfficientNet-B1은 ResNet-152보다 5.7배 이상 빠릅니다.
- transfer learning의 경우에도 DAT, GPipe를 포함한 최신 모델과 비교해봤을 때 8개의 데이터셋 중에서 5개는 정확도가 더 높으면서 9.6배 더 적은 파라미터를 사용했습니다.

[그림 8] EfficientNet-B0 baseline network
- 실험 결과, single-dimension scaling 방식은 정확도가 향상됨에 따라 FLOPS 역시 늘어나는 문제가 있습니다. 반면 compound scaling의 경우 정확도를 최대 2.5% 이상 늘리면서 FLOPS는 늘어나지 않습니다.
Conclusion
EfficientNet은 CNN 모델 설계 방식에 패러다임을 바꾼 유의미한 모델이라고 생각합니다. 그 동안 당연히 모델의 크기를 늘리면 모델의 복잡도가 늘어나는 것으로만 알았던 저에게도 큰 공부가 되었던 것 같습니다. 논문을 읽으면서 AutoML 기반의 모델들을 공부할 필요성을 느꼈습니다. 천천히 읽어보려고 했지만 최근 Kaggle 대회에서 대부분 EfficientNet 기반의 모델을 사용한지라 개인적으로 궁금해서 다 건너뛰고 먼저 읽어보았습니다. 다음 포스팅에서는 EfficientNet 기반 Object detection 모델인 EfficientDet에 대해 살펴보도록 하겠습니다.
References
EfficientNet 논문
컴퓨터 비전 논문들에 대해 잘 정리되어 있는 hoya님의 블로그
EfficientNet 논문을 잘 정리한 블로그
